1. Distribusi Binomial
Pada umumnya suatu eksperimen dapat dikatakan eksperimen Binomial apabila memenuhi 4 syarat sebagai berikut.
- Banyaknya eksperimen merupakan bilangan tetap (fixed number of trial).
- Setiap eksperimen mempunyai 2 hasil yang dikategorikan menjadi “sukses” dan “gagal”. Dalam aplikasinya, harus kategori apa yang disebut sukses tersebut.
- Probabilitas sukses nilainya sama pada setiap eksperimen.
- Eksperimen tersebut harus bebas (independent) satu sama lain, artinya eksperimen yang satu tidak mempengaruhi hasil eksperimen hasil eksperimen lainnya.
Dalam distribusi probabilitas Binomial, dengan n percobaan, berlaku rumus berikut

Apabila suatu himpunan yang terdiri dari n elemen dibagi dua, yaitu x sukses dan (n – x) gagal, maka banyaknya permutasi dari n elemen yang diambil x setiap kali dapat dihitung berdasarkan rumus berikut.

Masing-masing probabilitas pada distribusi Binomial dihitung sebagai berikut.
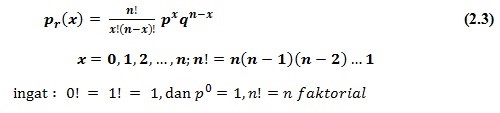
Contoh 1.1
Suatu mata uang logam Rp50 dilemparkan ke atas sebanyak 3 kali. X= banyaknya gambar burung (B) yang terlihat. p(probabilitas untuk mendapatkan B) = 1/2. B = sukses, b = gagal. Hitung Pr(0), Pr(1), Pr(2), Pr(3).
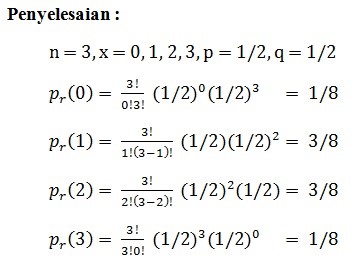
-
Rata-rata dan Varians Distribusi Binomial
Kita mengetahui bahwa untuk mencari rata-rata, kita menggunakan rumus
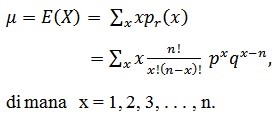
Sedangkan untuk menentukan varians dari distribusi binomial, kita menggunakan rumus
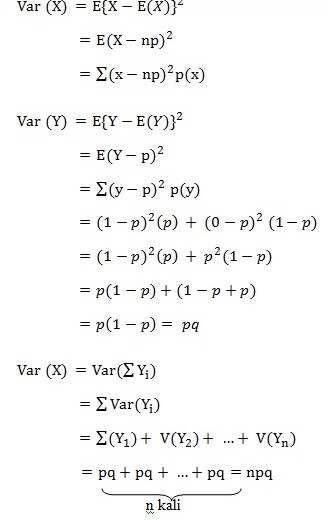
Jadi, varians dari distribusi binomial adalah npq. Dengan demikian, dapat disimpulkan bahwa untuk variabel X yang mengikuti distribusi binomial berlaku rumus berikut.
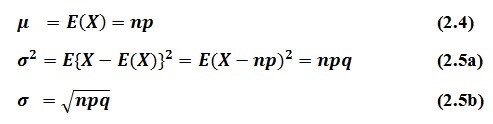
Contoh 1.2
Satu mata uang logam Rp50 dilemparkan ke atas sebanyak 4 kali, di mana probabilitas munculnya gambar burung (P(B)) sama dengan probabilitas munculnya gambar bukan burung P(B) – 1/2. Jika X = banyaknya gambar burung (B) yang muncul, carilah nilai rata-rata (E(X)) dan simpangan bakunya dengan menggunakan cara : a) Perhitungan secara langsung. b) Dengan menggunakan rumus E(X) = np,


2. Distribusi Poisson
Distribusi poisson yaitu pengembangan satu bentuk distribusi binomial yang mampu mengakulasikan distribusi probabilitas dengan kemungkinan sukses (p) sangat kecil dan jumlah eksperimen (n) sangat besar. Distribusi ini biasanya digunakan untuk menghitung nilai probabilitas suatu kejadian dalam suatu selang waktu dan daerah tertentu. Sebagai contoh, banyaknya dering telepon dalam satu jam di suatu kantor, banyaknya kesalahan ketik dalam satu halaman laporan, banyaknya bakteri dalam air yang bersih, banyaknya presiden meninggal karena kecelakaan lalu lintas. Distribusi poisson digunakan untuk menghitung probabilitas suatu kejadian yang jarang terjadi. Rumus untuk menyelesaikan distribusi Poisson adalah sebagai berikut.

-
Karakteristik dan Proses Distribusi Poisson
Pada contoh distribusi kendaraan yang melalui jalan bebas hambatan Jagorawi pada jam-jam sibuk seperti ini
- Rata-rata hitung kendaraan yang lewat pada jam-jam sibuk dapat diketahui dari data lalu lintas terdahulu.
- Apabila jam-jam sibuk kita bagi dalam detik, maka akan diperoleh :
- Kemungkinan secara tepat sebuah kendaraan akan lewat setiap satu detik, dan begitu seterusnya pada selang satu detik.
- Kemungkinan dua atau lebih kendaraan akan lewat setiap satu detik (jumlah ini kecil sekali) sehingga kita anggap sebagi nilai nol.
- Banyaknya kendaraan yang lewat pada suatu detik tertentu tidak ada hubungannya dengan banyaknya kendaraan yang lewat pada setiap detik saat jam-jam sibuk.
- Banyaknya kendaraan yang lewat pada suatu detik tidak bergantung terhadap banyaknya kendaraan yang lewat pada detik yang lain.
Oleh karena itu, secara umum kondisi di atas dapat terjadi pula pada setiap proses. Apabila kondisi di atas ditemui dalam suatu kasus maka kita dapat menggunakan rumus distribusi Poisson
-
Mengitung Probabilitas dengan Distribusi Poisson
Apabila X (huruf besar) dianggap mewakili suatu variabel sembarang dan merupakan bilangan bulat, maka kejadian x dalam distribusi Poisson dapat dihitung sebagai berikut.

-
Rata-rata dan Varians, Distribusi Poisson
Dapat dibuktikan bahwa untuk distribusi Poisson,

3. Distribusi Hipergeometrik
Perbedaan antara distribusi hipergeomerik dengan binomial adalah bahwa pada distribusi hipergeometrik, percobaan tidak bersifat independen (bebas). Artinya, antara percobaan yang satu dengan yang lainnya saling berkait. Selain itu probabilitas “SUKSES” berubah (tidak sama) dari percobaan yang satu ke percobaan lainnya. Notasi-notasi yang biasanya digunakan dalam distribusi hipergeometrik adalah sebagai berikut : r : menyatakan jumlah unit/elemen dalam populasi berukuran N yang dikategorikan atau diberi label “SUKSES” N – r : menyatakan jumlah unit/elemen dalam populasi diberi label “GAGAL” n : ukuran sampel yang diambil dari populasi secara acak tanpa pengambilan (without replacement) x : jumlah unit/elemen berlabel “SUKSES” di antara n unti / elemen Untuk mencari probabilitas x sukses dalam ukuran sampel n, kita harus memperoleh x sukses dari r sukses dalam populasi, dan n – x gagal dari N – r gagal. Jadi, fungsi probabilitas hipergeometrik dapat dituliskan sebgai berikut.

Perhatikan bahwa terdapat dua persyaratan yang harus dipenuhi oleh sebuah distribusi Hipergeometrik :
- Percobaan diambil dari suatu populasi yang terbatas, dan percobaan dilakukan tanpa pengembalian (without replacement).
- Ukuran sampel n harus lebih besar daripada 5% dari populasi N (5% dari N). Dari rumus 2.9 di atas, perhatikan bahwa
Contoh 1.3
Sebuah anggota komite terdiri dari 5 orang, di mana 3 adalah wanita dan 2 laik-laki. Misalkan 2 orang dari 5 anggota komite tersebut dipilih untuk mewakili delegasi dalam sebuah konvensi/pertemuan.
(i) Berapa probabilitas bahwa dari pemilihan secara acak didapat 2 orang wanita?
(ii) Berapa probabilitas dari 2 orang yang terpilih adalah 1 laki-laki dan 1 wanita?

4. Distribusi Multinomial
Dalam distribusi mutinomial, sebuah percobaan akan menghasilkan beberapa kejadian (lebih dari 2) yang saling meniadakan / saling lepas (mutually exclusive).
-
Fungsi Distribusi Multinomial

Contoh 1.4
Proses pembuatan pensil dalam sebuah pabrik melibatkan banyak buruh dan proses tersebut terjadi berulang-ulang. Pada suatu pemeriksaan terakhir yang dilakukan telah memperlihatkan bahwa 85% produksinya adalah “baik”, 10% ternyata “tidak baik tetapi masih bisa diperbaiki” dan 5% produksinya “rusak dan harus dibuang”. Jika sebuah sampel acak dengan 20 unit terpilih, berapa peluang jumlah unit “baik” sebanyak 18, unit “tidak baik tetapi bisa diperbaiki” sebanyak 2 dan unit “rusak” tidak ada?

5. Distribusi Normal
Distribusi normal merupakan distribusi kontinu yang mensyaratkan variabel yang diukur harus kontinu, misalnya tinggi badan, berat badan, skor IQ, jumlah curah hujan, isi botol Coca-cola, hasil ujian, dan sebagainya.
-
Kurva Normal
Suatu variabel acak kontinu X, yang memiliki distribusi berbentuk lonceng seperti yang diperlihatkan dalam Peraga 2.2, disebut variabel acak normal. Fungsi kepadatan probabilitas normal dapat dituliskan sebagai berikut.
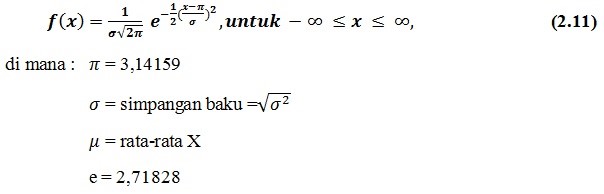

Perlu diketahui di sini bahwa rata-rata dan varians distribusi normal adalah sebagai berikut.
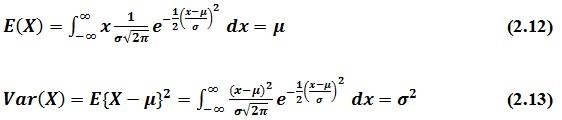
Fungsi distribusi atau distribusi kumulatif dari fungsi normal adalah sebagai berikut.

-
Distribusi Normal Baku (Standar)
Untuk mengubah distribusi normal menjadi distribusi normal baku (standar) adalah dengan cara mengurangi nilai-nilai variabel X dengan rata-rata dan membanginya dengan standar deviasi sehingga diperoleh variabel baru Z.

Variabel normal baku Z mempunyai rata-rata = 0 dan standar deviasi = 1.
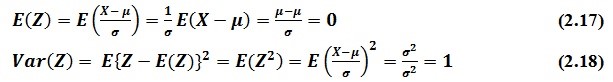
6. Distribusi Kai-Kuadrat (X kuadrat = Chi Square)
Distribusi kai-kuadrat sangat berguna sebagai kriteria untuk pengujian hipotesis mengenai varians dan juga untuk uji ketepatan penerapan suatu fungsi (test goodness of fit) apabila digunakan untuk data hasil observasi atau data empiris. Dengan demikian, kita dapat menentukan apakah distribusi pendugaan berdasarkan sampel hampir sama atau mendekati distribusi teoritis, sehingga kita dapat menyimpulkan bahwa populasi dari mana sampel itu kita pilih mempunyai distribusi yang kita maksud (misalnya, suatu populasi mempunyai distribusi Binomial, Poisson, atau Normal).
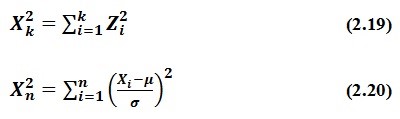
Bentuk kurva kai-kuadrat sangat dipengaruhi oleh besar-kecilnya nilai derajat kebebesan. Makin kecil nilai derajat kebebasan, bentuk kurvanya makin menceng ke kanan dan makin besar nilai derajat kebebasan bentuk kurvanya makin mendekati bentuk fungsi normal. Kai-kuadrat merupakan fungsi kontinu dan nilainya tidak pernah negatif. Nilai rata-ratanya makin meningkat kalau nilai derajat kebebasan juga makin meningkat.

Untuk v > 100, distribusi kai-kuadrat mendekati distribusi normal, di mana variabel Z sebagai variabel normal baku dapat diperoleh dengan cara berikut.
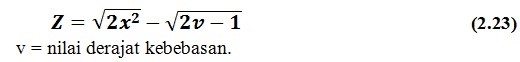
-
Cara Membaca Tabel X kuadrat
Dalam tabel, derajat kebebasan sering diberi simbol v, r, atau n dan sering disingkat d.o.f atau d.f. Dalam membaca tabel kai-kuadrat, agar diperhatikan simbol (notasi) di bagian atas yang digunakan dalam tabel tersebut. Tabel Kai-Kuadrat memuat nilai X kuadarat, dan bukan nilai probabilitas seperti halnya tabel distribusi normal.

7. Distribusi F

Distribusi F memungkinkan ahli ekonomi untuk menguji asumsi mengenai tepatnya fungsi produksi, fungsi permintaan dan fungsi konsumsi untuk diterapkan terhadap data empiris atau data hasil observasi; memungkinkan ahli pemasaran untuk menguji pendapatnya bahwa harga beras sama di beberapa pasar di Jakarta; memungkinkan ahli riset pertanian untuk menguji hipotesis bahwa tidak ada perbedaan pengaruh yang berarti dari berbagai varietas dan lain sebagainya.

Distribusi F ini ditemukan oleh R.A. Fisher pada awal tahun 1920 dan berguna sekali bagi para “research worker” untuk menguji hipotesis mengenai suatu parameter dari beberapa populasi (lebih dari 2). Di dalam praktek, seringkali diperlukan nilai F sebagai batas bawah. Untuk itu, perlu diperhatikan bahwa kebalikan dari F juga merupakan F, namun dengan derajat kebebasan yang ditukar.
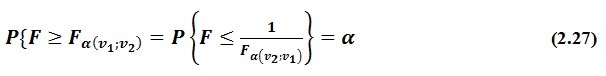
8. Distribusi t
Distribusi t selain digunakan untuk menguji suatu hipotesis juga untuk membuat pendugaan interval (interval estimate). Biasanaya distribusi t digunakan untuk menguji hipotesis mengenai nilai parameter, maksimal 2 populasi (jika lebih dari 2, harus digunakan F), dan dari sampel yang kecil (small sample size). Distribusi t dapat digunakan oleh pejabat perbankan; oleh seorang ahli senam hamil; oleh seorang ahli pemasaran ; oleh seorang ahli ekonomi; oleh pejabat perpajakan; oleh pejabat pemerintah dan lain sebagainya.

Artinya, fungsi mempunyai distribusi t dengan derajat kebebasan sebesar v.